
2 September 2025
How to build ML pipelines that increase your ROI

Solutions
Share with


Tech founders get the promise of AI, but too many projects die in no-man’s-land: great prototype, zero business impact. Years into the AI wave, proofs of concept still collapse before they make a dime.
The missing link? Machine learning pipelines. They’re the backbone that turns a custom software product from a cool demo into real revenue.
Talent is scarce, markets are crowded, and growth waits for no one. Leak at any stage — data, training, deployment — and your “competitive edge” is just an expensive experiment. Pipelines that actually deliver ROI aren’t optional anymore.
Brainence has seen the difference the right team makes. Deep expertise, niche skills, seamless integration — that’s what lifts projects out of proof-of-concept purgatory and into growth mode. Every pipeline we build has a measurable path to increasing your ROI.
In this article, we’ll cut through the noise with practical strategies to design pipelines that scale, avoid pitfalls, and turn a high-risk bet into a reliable revenue driver.
Read on.
Table of contents
What is a machine learning pipeline?
TL;DR: A machine learning pipeline is an end-to-end system that turns raw data into actionable AI-driven insights. It connects data ingestion, model training, validation, deployment, and monitoring, so AI delivers consistent, measurable business value.
Think of it as the engine room of AI. Pipelines move data through cleaning, feature engineering, model training, validation, deployment, and ongoing monitoring. Done right, they keep your AI reliable, scalable, and worth the investment.
Picture a relay race: each stage passes the baton to the next. If one runner stumbles — bad data, broken deployment — the whole team slows down, and ROI drifts out of sight.
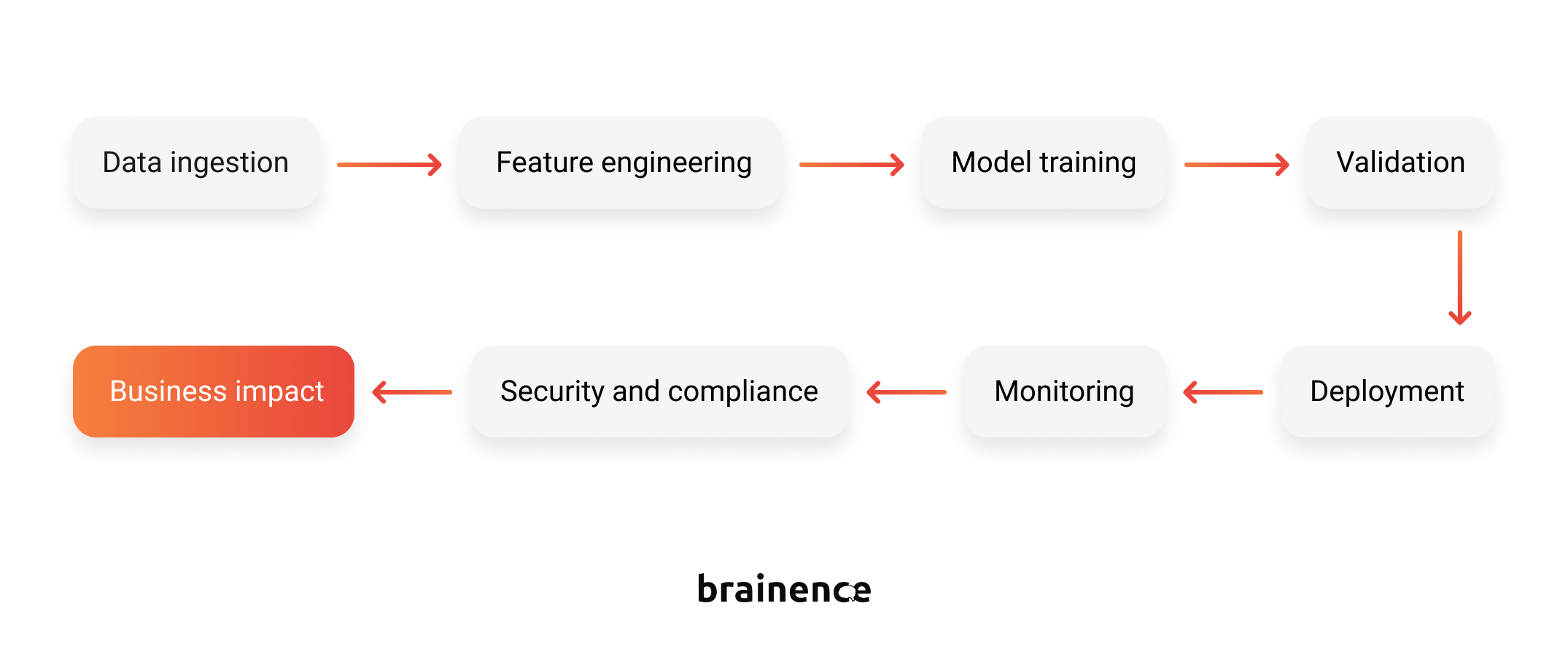
For tech leads, pipeline health = business impact. The better engineered and maintained, the more predictable your outcomes.
Bottom line: pipelines built with cost, speed, and business goals in mind are what move AI from lab experiments into real-world value.
Core components of ML pipelines that determine ROI
Building ML pipelines that actually pay off means focusing on the spots where costs, risks, and opportunities intersect. If you’ve been wondering how to optimize ML pipeline design for both performance and ROI, these are the exact components that decide whether your pipeline fuels growth or just burns budget.
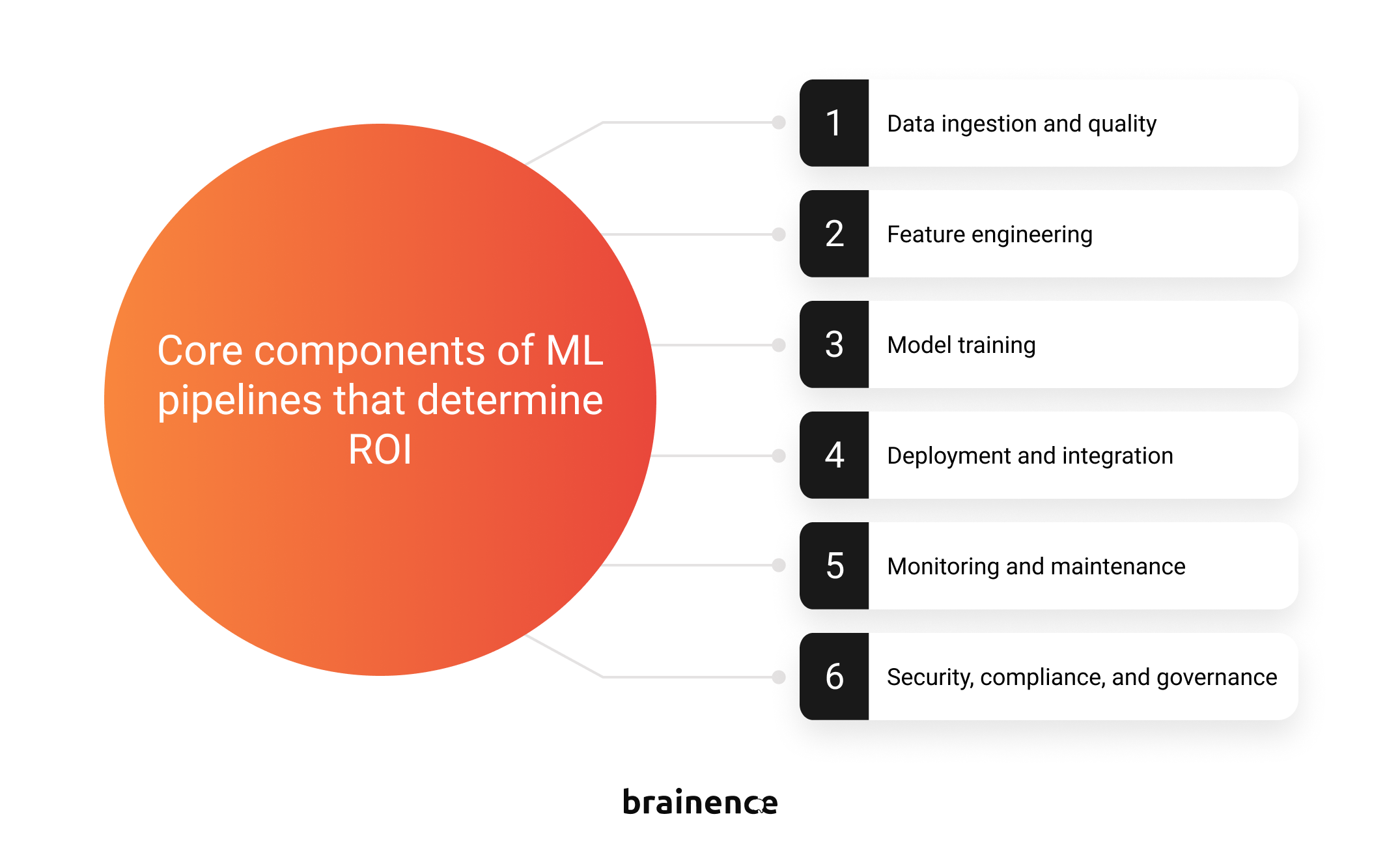
1. Data ingestion and quality
Data ingestion is the foundation. Your primary task is ensuring that the data getting in is clean, consistent, and usable. Skip that, and your team ends up firefighting bad inputs that snowball into broken models and downtime.
High data quality isn’t a “nice-to-have”; it’s a gating factor for ROI. Poor data means endless retraining, debugging, and manual fixes. It also kills confidence: data scientists stop trusting their models, execs stop trusting AI altogether.
Invest in scalable validation: schema checks, anomaly detection, freshness monitoring. A smarter ingestion layer cuts manual work and ties outputs directly to business outcomes.
2. Feature engineering
Feature engineering often gets mistaken for “more is better.” In fact, more features usually mean longer training, higher compute bills, and more risk of overfitting or data leakage. Translation: bloated costs, slower cycles, and… reduced ROI.
The real value lies in prioritization. The most effective teams focus only on features that have a clear, measurable connection to business KPIs — whether that’s revenue growth, cost efficiency, or risk reduction.
Consider e-commerce: engineered features might include customer lifetime value segments or purchase frequency. In fraud detection, strong predictors often come from transaction velocity or geo-location anomalies. These features aren’t chosen at random — they’re grounded in proven business impact.
The smartest pipelines keep feature sets lean. By pruning aggressively, they achieve faster training, more resilient models, and a direct line of sight between model outputs and business results.
3. Model training
Training models is your balancing act: enough precision to drive business value without blowing budgets on endless compute cycles. Chasing that last 1% of accuracy can cost more than it’s worth.
That’s why techniques like transfer learning and model pruning are game-changers. Transfer learning reuses pre-trained models to cut training time and compute costs. Pruning slims down models by trimming excess parameters, speeding up inference, and reducing infrastructure demands.
The smartest teams aim for “good enough” accuracy tied to business thresholds, not perfection for perfection’s sake. The payoff: faster iterations, lower cloud bills, smoother deployments — and AI that delivers a real competitive edge instead of a massive invoice.
4. Validation
Validation is the stress test before you set models loose in the real world. Skip it, and you risk shipping models that look fine in training but collapse under live conditions, burning both time and credibility.
This stage is about proving generalization. That means testing on holdout datasets, running cross-validation, and checking for bias or leakage. The goal isn’t academic benchmarks; it’s confirming that models hold up against messy, unpredictable business data.
Strong validation also acts as an early ROI filter. It prevents overfitted models from slipping through and ensures only those that meet business-driven thresholds move forward. In other words, validation is what keeps ML pipelines from being science experiments and turns them into reliable, revenue-ready assets.
5. Deployment and integration
Deployment is where engineering meets business reality. Even the most accurate model is useless if it can’t plug smoothly into existing systems and workflows. Treat it as an afterthought, and you’ll be stuck with brittle scripts, manual handoffs, and a growing pile of technical debt.
Automation is the fix. Continuous delivery pipelines make releases fast, repeatable, and low-risk. They keep models fresh, reduce rollbacks, and save teams from costly firefighting.
Integration is equally critical. ML outputs should flow into real decisions, not sit in dashboards no one reads. When deployment and integration run like clockwork, AI stops being an experiment and starts acting like a revenue engine.
6. Monitoring and maintenance
Launching a model is not your finish line. It’s just the starting gun. Real-world data shifts, evolving user behavior, and markets evolve. As a result, data drift and model decay quietly chip away at performance.
For tech leads, monitoring means more than uptime or latency dashboards. The goal is to connect model signals directly to business outcomes and to spot trouble before it hits revenue, customer trust, or compliance.
In practice, that requires automated alerts, anomaly detection, and performance dashboards tied to KPIs like conversion rates, fraud detection accuracy, or cost savings. Add retraining schedules, validation cycles, and rollback plans, and you’ve got a system built to stay aligned with shifting realities.
If you’re asking how to optimize an ML pipeline for long-term business impact, monitoring and maintenance are what turn ML pipelines from fragile experiments into resilient, revenue-protecting assets.
7. Security, compliance, and governance
Cutting corners on security or compliance in ML pipelines is a false economy. What you save in the short term, you’ll likely pay back with interest in reputational damage, legal exposure, or stalled deployments.
Security means protecting the entire data lifecycle — from ingestion to model outputs — against breaches, poisoning attacks, and misuse. Compliance adds another layer: regulations like GDPR, HIPAA, or sector-specific standards shape not only what you build but how you build it.
Governance is the glue. It’s the system of checks, documentation, and audit trails that lets you scale without losing control. Strong governance makes it obvious who changed what, when, and why — reducing both technical chaos and regulatory risk.
The upside of doing this well? Security and compliance stop being “innovation blockers”. Instead, they become competitive advantages: enabling faster moves, easier partnerships, and confident entry into regulated markets.
Get your ML pipeline right the first time
Partner with Brainence to build scalable, cost-efficient ML pipelines that deliver measurable ROI from day one.

Common pitfalls and ROI-killers in ML pipelines
Most ML pipelines rarely fail in one dramatic technical collapse; they degrade through a series of engineering and operational compromises. Blame inefficiency, misalignment, and unchecked costs. What looks like “a small optimization delay” in month one often compounds into systemic underperformance by month twelve.
The key question: where do projects typically stumble, and how can you avoid the traps that quietly eat into financial returns?

1. Starting without a quantifiable business objective
This is the silent killer of ML ROI. Up to 85% of projects fail to deliver measurable value, often because they launch without a clear business metric in sight. As a result, pipelines that run perfectly in technical terms might drift into irrelevance.
What does it look like in practice?
- A recommendation engine with no link to revenue attribution.
- A predictive maintenance model without a cost-savings baseline.
- A churn model that flags at-risk customers but never connects to retention workflows.
The result: no way to prove business impact. Teams optimize for accuracy, latency, or precision, while leadership evaluates profitability, efficiency, or market share. The mismatch stalls pilots, shrinks budgets, and kills the “AI win.”
The fix: ruthless clarity. Define the financial or operational lever before writing a single line of pipeline code. Tie the model output to metrics that show up in quarterly reports: recommendation accuracy linked to revenue per user, predictive maintenance tied to downtime reduction, churn scores tied to retention rate.
An ML pipeline without a business objective is like a GPS without a destination: it might run smoothly, but you’ll have no idea where you’re going, or why you started the trip in the first place.
2. Overengineering for perfection
Perfectionism is seductive. Teams chase that extra 0.2% accuracy, thinking it will magically drive business success. Each tweak adds weight: more parameters, higher inference latency, bigger compute bills, and trickier integrations.
Why it fails in production:
- The tiny accuracy gain often comes with million-dollar trade-offs: larger GPU clusters, longer retraining cycles, and more deployment tickets.
- By the time the “perfect” model ships, business needs may have shifted, customers evolved, or competitors moved ahead.
The fix: favor pragmatism over perfection. Balance accuracy with latency, cost, and adaptability. Speed of iteration usually beats microscopic precision in the real market.
3. Data quality debt at ingestion
The ingestion layer is where most ROI leakage begins. Poor data quality is widespread: 73% of executives report dissatisfaction with their organization’s data, and 61% say they can’t turn data into a competitive advantage. IBM estimates that ignoring this costs companies around USD 15 million per year.
What does it look like in production?
- Schema drift, missing values, duplicate records, inconsistent timestamps. These issues trigger retraining cycles, cascading errors, and extended debugging sessions.
- Manual triage becomes the norm. Teams spend hours or days tracking down bad data, slowing progress, and eroding trust. Leadership notices delays and asks, “Where’s the ROI?”
- Reactive fixes dominate. Corrections grow from hours into days or weeks, long after models are deployed and budgets stretched.
The fix: observability, not hindsight. Tools that monitor data freshness, schema consistency, and volume anomalies at the source turn reactive firefighting into proactive resolution.
Start with clean, reliable data, and everything downstream — from model accuracy to KPIs — is more likely to deliver real business value.
4. Integration as an afterthought
Building an ML pipeline without planning integration from the start is a trap for even seasoned teams. It’s tempting to focus on models and data transformations in isolation (the flashy part!). But when you deploy your pipeline into live production systems, reality hits hard.
What goes wrong in production?
- APIs are contracts. If the inference pipeline can’t communicate smoothly with services, orchestration tools, or data warehouses, teams often face extra debugging, rewrites, and fragile workarounds.
- Security and compliance add complexity. Retrofitting authentication, logging, or audit requirements late can slow deployment and increase operational friction.
- Pipelines that run fine in notebooks or dev environments frequently fail to scale under production loads. These “proofs of concept” may never become reliable business assets.
The fix: plan integration early. Collaborate between data scientists, engineers, and operations. Build reusable connectors, automate deployment, and embed security checks from day one. That’s how you turn fragile prototypes into durable business assets.
5. No proactive performance monitoring
Model drift, data drift, and concept drift happen continuously. The patterns your model learned yesterday won’t always hold tomorrow. Without automated, continuous monitoring, these shifts quietly erode accuracy and reliability.
What goes wrong without monitoring?
- Bad predictions propagate downstream in fraud detection, customer segmentation, or supply chain forecasting.
- Manual checks or waiting for customer complaints catch problems too late, slowing response and risking revenue or trust.
The fix: embed monitoring from day one. Track model metrics alongside input data, flag anomalies, and trigger retraining or rollback automatically. Continuous observability turns ML pipelines from fragile experiments into reliable, revenue-generating assets.
6. Underestimating operational costs
Real-time or high-throughput workloads don’t scale linearly. Costs spike with data volume, query complexity, and model refresh rates.
What goes wrong if you ignore it?
- Unexpected bills for GPU clusters spinning idle or data transfers surging after a launch.
- Budget overruns from architectural blind spots. Pipelines that looked healthy on paper become expensive money pits.
The fix: build cost observability into every layer. Use spot instances, optimize batch sizes, automate resource shutdowns, and leverage caching strategies. Keep the pipeline lean, predictable, and ready to scale without breaking the bank.
Industry-focused examples: ML pipeline decisions that deliver ROI
The blueprint for ML pipeline ROI changes with the industry. The tech stack may rhyme, but the decisions that move the needle are context-specific. Here’s how it plays out in four high-impact sectors we’ve been working in for years.
Healthcare
In healthcare, an ML pipeline that ignores compliance and explainability is a lawsuit waiting to happen. HIPAA and GDPR regulations demand auditable decisions and full traceability of model outputs.
ROI play: build pipelines with model versioning, encrypted data storage, and explainability tools like SHAP or LIME. For example, Mount Sinai developed an AI model to predict delirium in hospitalized patients. By alerting care teams to high-risk patients, detection and intervention rates quadrupled, improving patient outcomes in real-world clinical practice
Retail
Retail pipelines live or die on latency. Batch processing that’s “good enough” for reporting kills the upsell opportunity if the customer has already clicked away.
ROI play: Shift from daily ETL to streaming ingestion (e.g., Kafka, Flink) to enable same-session recommendations. Amazon’s ML-powered personalization system continuously retrains on live clickstream and transaction data, driving a documented revenue lift through increased average order value and conversion rates.
Manufacturing
A manufacturer’s worst enemy is unplanned downtime. ML pipelines that seamlessly merge high-frequency IoT sensor data with historical maintenance logs can predict failures days or weeks in advance.
ROI play: Implement feature stores to standardize sensor-derived variables, enabling retraining without manual data wrangling. For instance, an aluminum manufacturer deployed Siemens’ Senseye Predictive Maintenance, reducing unplanned downtime by 20%, improving operating efficiencies, and achieving ROI within 4 to 6 months.
Government
Government agencies handle vast, siloed datasets, often updated at inconsistent intervals. Without standardization and automated validation, data becomes politically risky and operationally useless.
ROI play: Establish interoperability layers and automated data quality checks across agencies. For instance, HM Revenue and Customs (HMRC) employs the Connect system, a data mining tool that cross-references tax records with other databases to identify fraudulent activities. This system has been instrumental in uncovering undeclared income and has led to significant recoveries of lost revenue.
Bottom line here? ROI in ML pipelines doesn’t come from “having AI.” It comes from making design choices that are ruthlessly aligned with the operational and regulatory realities of the industry.
Turn your ML pipelines into predictable growth engines
Our expert teams build and plug in scalable ML pipelines that actually move the needle, aligned with your business goals and ready yesterday.
Scale ML impact: pipelines that drive real growth
We see companies treat ML pipelines like boring plumbing: just a way to move data around and shove models into production. In reality, when you design them right, pipelines are strategic infrastructure: they speed up time-to-market, cut the cost of experimentation, and make every new ML initiative hit harder and faster.
Step 1. Shift from project thinking to platform thinking
Early ML efforts tend to be siloed: the fraud detection team builds one workflow, the marketing analytics team builds another. These one-off approaches work in isolation but collapse under the weight of scale — each new use case demands fresh integrations, custom tooling, and repeated engineering effort.
The strategic upgrade:
Treat your pipeline as an enterprise-wide ML platform. Ingestion, transformation, training, deployment, and monitoring capabilities are built once, made reusable, and shared across teams.
Example: Netflix’s Metaflow allows data scientists to build and deploy ML projects without reinventing infrastructure. The same backbone powers personalization in recommendations, visual artwork selection, and streaming optimization.
Step 2. Build for continuous learning, not static delivery
Models degrade over time — user behavior changes, market conditions shift, and data drifts. A pipeline that ends at “model deployed” is a liability; one that supports continuous monitoring, retraining, and safe redeployment is an asset.
The strategic upgrade:
Adopt MLOps principles with automated drift detection, retraining triggers, feature store updates, and rollback plans — making model quality self-sustaining.
Example: Uber’s Michelangelo platform powers hundreds of models across pricing, ETA predictions, and fraud detection. Continuous feedback loops allow Uber to spot degradation quickly and restore performance before it hits customer experience.
Step 3. Tie technical scalability directly to business scalability
Scaling AI impact isn’t just about bigger models — it’s about multiplying value without multiplying cost. A modular, componentized pipeline allows teams to launch new models by reusing connectors, validation routines, and deployment templates.
The strategic upgrade:
Design every pipeline improvement so it reduces the marginal cost of the next AI use case.
Example: Shopify uses a modular ML pipeline architecture to adapt search ranking, recommendations, and inventory forecasting models to thousands of merchants. Each improvement benefits the entire merchant base without rebuilding from scratch.
Start building ML pipelines that pay off
Forget the buzzwords and the endless chase for the latest ML pipeline tools. What matters is putting together systems that are reliable, scalable, and cost-efficient. The kind that don’t just shine in a demo but hold up in production, grow with your business, and actually show up on the bottom line.
At Brainence, we skip the junior mistakes or “best practices” that don’t fit your business. We assemble senior, niche expert teams who speak Kafka, Flink, MLOps, and model pruning fluently — people who can spot the trade-offs between accuracy and cost before your cloud bill makes you blink.
Our approach:
— Modular and reusable: pipelines built once, leveraged across teams.
— Transparent and robust: automated validation, explainability, and continuous monitoring baked in.
— Strategic infrastructure: designed to scale from one use case to dozens without reinvention.
Across healthcare, retail, telecom, and more, we’ve seen it all, and we balance security, compliance, latency, and operational cost — no compromises, no surprises.
Behind every great product is an expert team. We help you build both. Brainence bridges the talent gap with battle-tested specialists who integrate seamlessly, deliver measurable ML impact, and turn your pipelines from experimental projects into growth engines.
Contact us

The most impressive for me was the ability of the team to provide first-class development and meet all the deadlines.
COO, Replyco LTD,
United Kingdom

The team proactively comes up with solutions and is eager to deliver high-quality development support.
Executive, Software & Consulting Services Provider, Netherlands
I was blown away by the knowledge that Brainence has about web app development, UX and optimisation.
CEO, E-commerce Company,
United Kingdom
The project management was well-managed. We worked well together to create a refined product.
CTO, Field Service & Job Management Platform, Australia



